from lokigi.site import SiteProblemGetting Started
The lokigi package is designed to make it easier to undertake location analysis problems.
In many organisations - but particularly in healthcare - there is a need to be able to find a near-optimum combination of possible sites to minimize an objective. For example, you may be aiming to open an additional site to deliver healthcare services from, wanting to achieve a goal like minimizing the average travel time for each individual.
Excellent packages exist for finding optimum solutions, such as spopt. However, in healthcare scenarios in particular, providing only the optimum solution is often not ideal as these decisions are extremely complex and costly, and stakeholders need to understand the pros and cons of a range of near-optimal solutions to make an informed decision.
Enter lokigi.
Setting up a site location problem
First, we need to import the SiteProblem class from the lokigi.site module.
We will set up an instance of the SiteProblem class. Let’s just call this problem - but you could call it anything.
problem = SiteProblem()There are four core types of data we can add to our problem object:
- a travel time (or other ‘cost’) matrix
- site locations *
- per-region demand *
- a geographic dataset representing the region being explored *
* indicates optional datasets
The data you provide should take the following format.
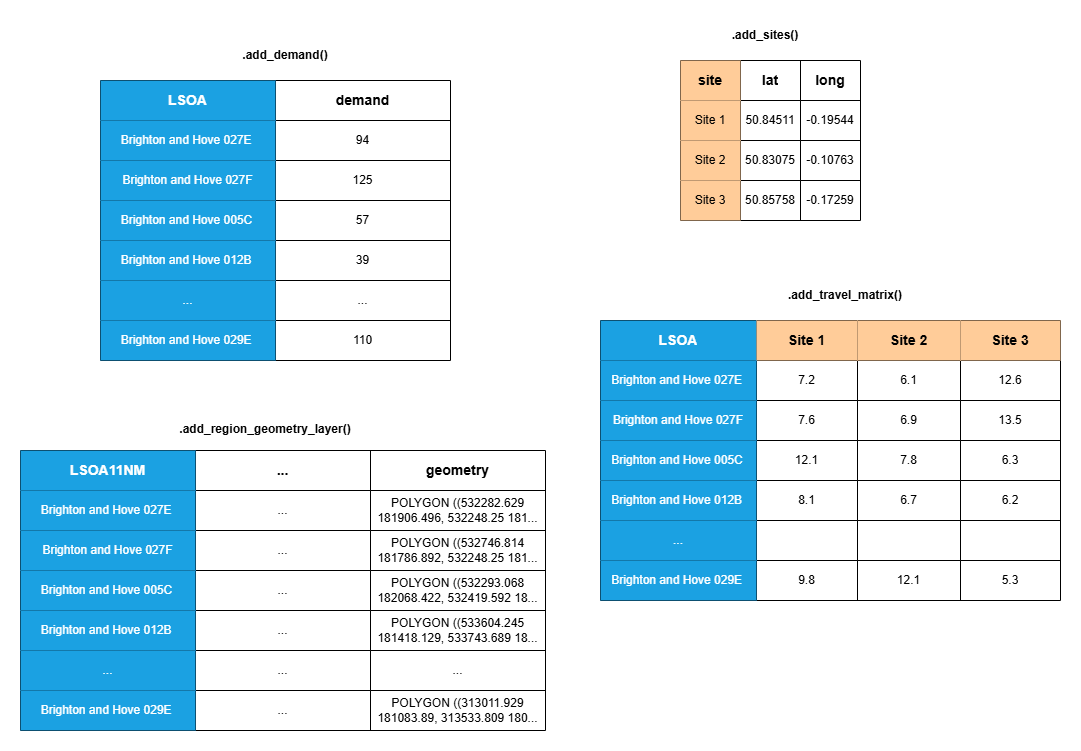
Remember - only the travel matrix is completely necessary. You can include any combination of the remaining data.
The columns in blue can contain any unit of geographical area. In the UK, this might be LSOA, OA, MSOA, postcode, postcode sector, and so on. The column names do not need to be consistent across the three datasets as you will specify which column contains that data in each case - in this example two use the name “LSOA” while the third uses “LSOA11NM”, for example.
Similarly, the columns in orange do not need to use the format shown. Your sites may have any names, as long as the names used in the site dataframe (if provided) are consistent with the names used for the columns in your travel matrix.
Adding a travel time (or other ‘cost’) matrix
The bare minimum we need to provide to be able to undertake a location problem is a travel matrix.
This is a grid of travel times - or another ‘cost’ parameter that you want to optimize for, like the distance.
The rows should represent where people would start their journey from.
The first column should contain the names of the places people would start their journey from. In location problems in a UK context, we often use something like LSOA or MSOA.
The remaining columns should represent where people would end their journey - i.e. all of your candidate sites. Here we will use names to represent each site; we can pass in exact coordinates or other details in a different step.
The values in each cell within your grid would be the cost parameter: the travel time, distance, or another option like CO2 emissions.
Here is an example dataset in the correct format.
| LSOA | Site 1 | Site 2 | Site 3 | |
|---|---|---|---|---|
| 0 | Brighton and Hove 027E | 773.93 | 527.69 | 444.29 |
| 1 | Brighton and Hove 027F | 757.39 | 499.11 | 517.57 |
| 2 | Brighton and Hove 027A | 763.24 | 601.38 | 517.98 |
| 3 | Brighton and Hove 029E | 743.62 | 651.72 | 660.36 |
| 4 | Brighton and Hove 029D | 665.85 | 664.65 | 658.20 |
Here, someone travelling from the LSOA Brighton and Hove 027E to site 3 would have a travel time of 7.4 minutes, versus 12.9 minutes if they went to site 1.
Tip
Want to know about different ways of organising geographic information in the UK?
Check out the subsection “What other ways do we determine areas within the UK” chapter of the HSMA geographic book.
We don’t have to use LSOAs for our rows, or site names for our columns - these could be anything! You might have postcode sectors for your rows and lat/long pairs for your columns, for example.
To add this data to our problem, we use the .add_travel_matrix() method of our SiteProblem instance.
- 1
- We can pass in either a pandas object or a link to a filepath (either on your computer or on the web).
- 2
-
We need to tell lokigi which column contains our ‘source’ data - i.e. the column that has the names of the locations people will be travelling from. It will then assume all other columns in the dataframe relate to the destinations; if this is not the case, the
skip_colsparameter must be provided so that any irrelevant columns can be ignored. - 3
- We can optionally convert the values in our travel matrix. This travel matrix records travel times in seconds, so we use that as our ‘from_unit’…
- 4
- … and we would prefer to display our times in minutes, so we provide that as the ‘to’ unit.
Tip
If we weren’t doing a conversion, we can just pass the ‘unit’ parameter to describe the unit used in our dataset, and this will then be picked up when we’re plotting our solution, so it’s worth specifying here.
If we’re doing a conversion, we don’t need to pass the ‘unit’ parameter too as lokigi will automatically set this using the ‘to_unit’.
Let’s now view our dataset.
problem.show_travel_matrix().head()| LSOA | Site 1 | Site 2 | Site 3 | Site 4 | Site 5 | Site 6 | |
|---|---|---|---|---|---|---|---|
| 0 | Brighton and Hove 027E | 12.898833 | 8.794833 | 7.404833 | 8.197500 | 10.125667 | 9.248500 |
| 1 | Brighton and Hove 027F | 12.623167 | 8.318500 | 8.626167 | 9.351167 | 9.649500 | 8.972833 |
| 2 | Brighton and Hove 027A | 12.720667 | 10.023000 | 8.633000 | 6.840000 | 11.353833 | 9.289167 |
| 3 | Brighton and Hove 029E | 12.393667 | 10.862000 | 11.006000 | 6.328667 | 12.193000 | 9.293000 |
| 4 | Brighton and Hove 029D | 11.097500 | 11.077500 | 10.970000 | 5.216667 | 12.408333 | 9.508500 |
We can see that we the travel times for every LSOA to 6 possible sites.
Note
At present, lokigi assumes you always want to minimize the cost parameter - i.e. you want people to travel the shortest distance or have the shortest travel time, or undertake journeys that emit the least amount of CO2.
If you need lokigi to be able to support maximising a cost objective, please raise an issue on the repository: https://github.com/hsma-tools/lokigi/issues
Tip
Lokigi doesn’t handle generating travel/cost matrices. It assumes you have already got this data to feed into it.
Interested in generating your own travel matrices in this format?
Check out the “Lookup Up Travel Times Using APIs” chapter of the HSMA geographic book.
Solving a simple problem
If we don’t have any other requirements, we can solve our problem right now!
Let’s solve by minimizing the average travel time from all ‘sources’ to all ‘destinations’ - which we can call a “simple p-median” problem.
We’ll assume we want to find the best possible combination of any 3 sites.
solutions = problem.solve(p=3, objectives="simple_p_median")/__w/lokigi/lokigi/lokigi/site.py:491: UserWarning:
No demand data was provided. Demand from all regions has been assumed to be equal.If you wish to override this, run .add_demand() to add your site dataframe before running .solve() again.You can use the .show_demand_format() to see the expected format beforehand.
/__w/lokigi/lokigi/lokigi/site.py:499: UserWarning:
No candidate site dataframe was given.
Sites names have been taken from the columns of your travel matrix: Site 1, Site 2, Site 3, Site 4, Site 5, Site 6.
If you wish to override this, run .add_sites() to add your site dataframe before running .solve() again.
You can use the .show_sites_format() to see the expected format beforehand.
This returns an object with the lokigi class SiteSolutionSet.
solutions<lokigi.site_solutions.SiteSolutionSet at 0x7fb4ea56b560>solutions.show_solutions()| solution_rank | site_names | site_indices | coverage_threshold | weighted_average | unweighted_average | 90th_percentile | max | proportion_within_coverage_threshold | problem_df | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | [Site 3, Site 4, Site 6] | [2, 3, 5] | None | 5.36 | 5.36 | 8.06 | 16.69 | 0.0 | LSOA Site 3 Sit... |
| 1 | 2 | [Site 3, Site 4, Site 5] | [2, 3, 4] | None | 5.45 | 5.45 | 8.50 | 16.69 | 0.0 | LSOA Site 3 Sit... |
| 2 | 3 | [Site 2, Site 3, Site 4] | [1, 2, 3] | None | 5.59 | 5.59 | 9.00 | 16.69 | 0.0 | LSOA Site 2 Sit... |
| 3 | 4 | [Site 1, Site 3, Site 4] | [0, 2, 3] | None | 5.67 | 5.67 | 9.36 | 16.69 | 0.0 | LSOA Site 1 Sit... |
| 4 | 5 | [Site 1, Site 3, Site 6] | [0, 2, 5] | None | 6.21 | 6.21 | 9.33 | 16.69 | 0.0 | LSOA Site 1 Sit... |
| 5 | 6 | [Site 3, Site 5, Site 6] | [2, 4, 5] | None | 6.29 | 6.29 | 9.26 | 16.69 | 0.0 | LSOA Site 3 Sit... |
| 6 | 7 | [Site 2, Site 3, Site 6] | [1, 2, 5] | None | 6.31 | 6.31 | 9.45 | 16.69 | 0.0 | LSOA Site 2 Sit... |
| 7 | 8 | [Site 1, Site 3, Site 5] | [0, 2, 4] | None | 6.32 | 6.32 | 9.70 | 16.69 | 0.0 | LSOA Site 1 Sit... |
| 8 | 9 | [Site 1, Site 2, Site 3] | [0, 1, 2] | None | 6.39 | 6.39 | 9.77 | 16.69 | 0.0 | LSOA Site 1 Sit... |
| 9 | 10 | [Site 2, Site 4, Site 6] | [1, 3, 5] | None | 6.64 | 6.64 | 11.58 | 22.86 | 0.0 | LSOA Site 2 Sit... |
| 10 | 11 | [Site 4, Site 5, Site 6] | [3, 4, 5] | None | 6.73 | 6.73 | 12.26 | 21.71 | 0.0 | LSOA Site 4 Sit... |
| 11 | 12 | [Site 2, Site 4, Site 5] | [1, 3, 4] | None | 6.76 | 6.76 | 11.32 | 21.71 | 0.0 | LSOA Site 2 Sit... |
| 12 | 13 | [Site 1, Site 4, Site 5] | [0, 3, 4] | None | 6.81 | 6.81 | 12.26 | 21.71 | 0.0 | LSOA Site 1 Sit... |
| 13 | 14 | [Site 1, Site 2, Site 4] | [0, 1, 3] | None | 6.92 | 6.92 | 11.93 | 23.92 | 0.0 | LSOA Site 1 Sit... |
| 14 | 15 | [Site 2, Site 3, Site 5] | [1, 2, 4] | None | 7.46 | 7.46 | 11.57 | 16.69 | 0.0 | LSOA Site 2 Sit... |
| 15 | 16 | [Site 1, Site 2, Site 6] | [0, 1, 5] | None | 7.54 | 7.54 | 11.90 | 22.86 | 0.0 | LSOA Site 1 Sit... |
| 16 | 17 | [Site 2, Site 5, Site 6] | [1, 4, 5] | None | 7.65 | 7.65 | 11.67 | 21.71 | 0.0 | LSOA Site 2 Sit... |
| 17 | 18 | [Site 1, Site 2, Site 5] | [0, 1, 4] | None | 7.66 | 7.66 | 11.67 | 21.71 | 0.0 | LSOA Site 1 Sit... |
| 18 | 19 | [Site 1, Site 4, Site 6] | [0, 3, 5] | None | 7.69 | 7.69 | 13.72 | 22.86 | 0.0 | LSOA Site 1 Sit... |
| 19 | 20 | [Site 1, Site 5, Site 6] | [0, 4, 5] | None | 7.70 | 7.70 | 12.65 | 21.71 | 0.0 | LSOA Site 1 Sit... |
We can produce a bar plot of the solutions, showing the variation between the best and worst.
solutions.plot_n_best_combinations_bar()Adding in geographic data
If we have a geojson, shp or geopackage file that represents the areas we are looking at, we can pass this in as well.
Here, we are passing in a geojson that contains the
- 1
- We pass in the pass to a geojson, shp or geopackage file. This can be located locally or on the web. If provided with a standard github link, it will automatically try to create the appropriate ‘raw’ link that it can download the file directly from.
- 2
- We pass in the name of the column in this geojson that should be used when trying to join to the other datasets - i.e. the column that acts as a bridge between the rows in our travel matrix and this geographic data. In our travel matrix, recall we have a column called “LSOA”. This contains the LSOA names in the same format as the “LSOA11NM” in our geographic dataset - so this is what we provide as our ‘common_col’.
Let’s take a look at the first few rows of this geographic data.
problem.show_region_geometry_layer().head(5)| FID | LSOA11CD | LSOA11NM | LSOA11NMW | BNG_E | BNG_N | LONG | LAT | GlobalID | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | E01000001 | City of London 001A | City of London 001A | 532123 | 181632 | -0.097140 | 51.51816 | a758442e-7679-45d0-95a8-ed4c968ecdaa | POLYGON ((532282.629 181906.496, 532248.25 181... |
| 1 | 2 | E01000002 | City of London 001B | City of London 001B | 532480 | 181715 | -0.091970 | 51.51882 | 861dbb53-dfaf-4f57-be96-4527e2ec511f | POLYGON ((532746.814 181786.892, 532248.25 181... |
| 2 | 3 | E01000003 | City of London 001C | City of London 001C | 532239 | 182033 | -0.095320 | 51.52174 | 9f765b55-2061-484a-862b-fa0325991616 | POLYGON ((532293.068 182068.422, 532419.592 18... |
| 3 | 4 | E01000005 | City of London 001E | City of London 001E | 533581 | 181283 | -0.076270 | 51.51468 | a55c4c31-ef1c-42fc-bfa9-07c8f2025928 | POLYGON ((533604.245 181418.129, 533743.689 18... |
| 4 | 5 | E01000006 | Barking and Dagenham 016A | Barking and Dagenham 016A | 544994 | 184274 | 0.089317 | 51.53875 | 9cdabaa8-d9bd-4a94-bb3b-98a933ceedad | POLYGON ((545271.918 184183.948, 545296.314 18... |
However, what’s more useful is plotting it.
problem.plot_region_geometry_layer()
This becomes more useful when we then solve the problem again.
solutions = problem.solve(p=3, objectives="simple_p_median")We can now plot the solution.
solutions.plot_best_combination()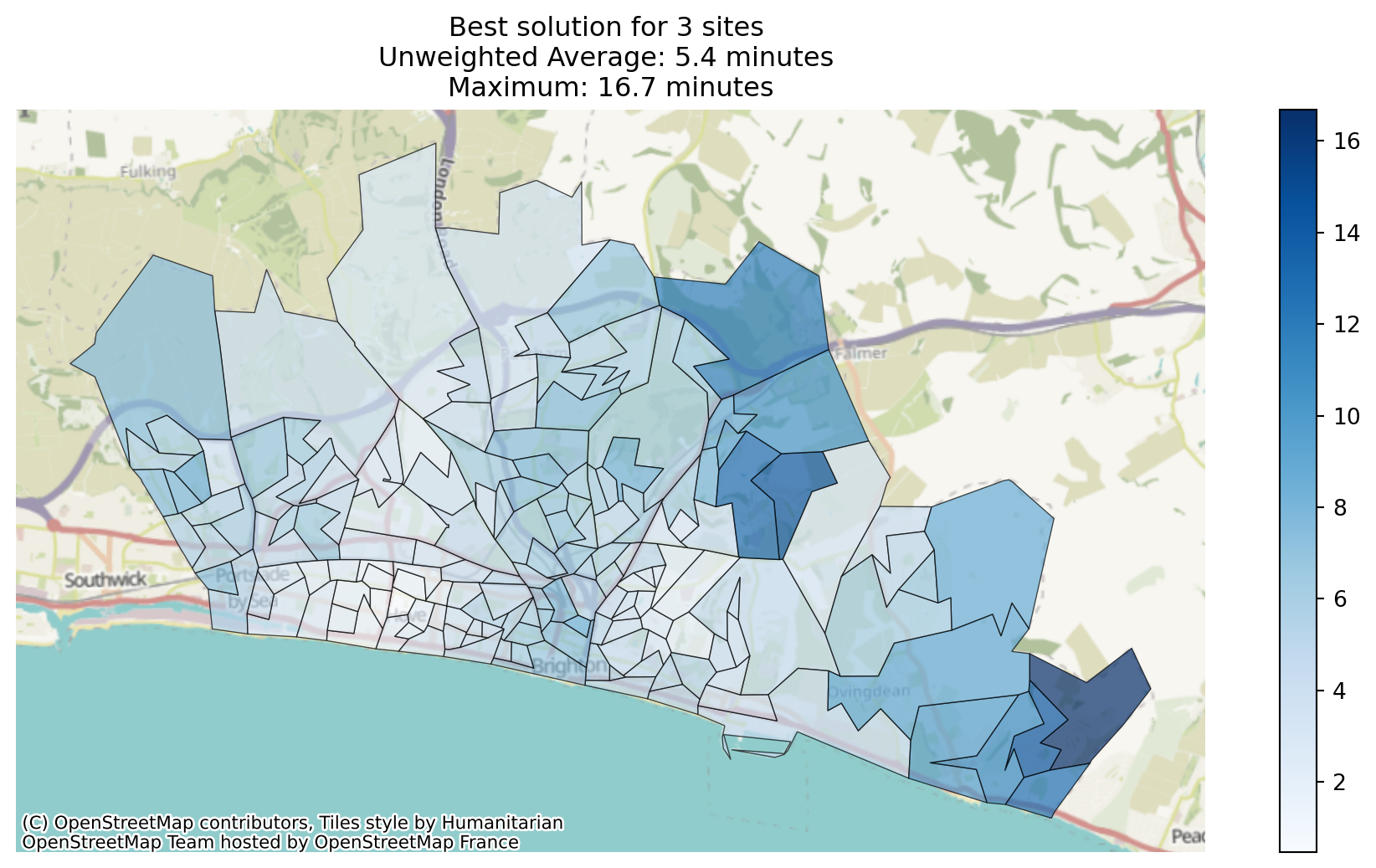
Adding in site data
However, it would be more useful if we could see the sites on the map.
Let’s load in a dataset containing the locations of our sites.
problem.add_sites(
candidate_site_df="../sample_data/brighton_sites.geojson",
candidate_id_col="site"
)
Note
As we’re passing in a dataset in a recognised geographic data format, it will look for a ‘geography’ column automatically. Alternatively, we could pass in a pandas dataframe or csv if it contains lat/long or eastings/northings, for example, specifying the ‘vertical’ geometry column and the ‘horizontal’ geometry column.
Let’s take a look at this data.
problem.show_sites()| canonical_site_index | site | geometry | |
|---|---|---|---|
| 0 | 0 | Site 1 | POINT (527142.275 106616.053) |
| 1 | 1 | Site 2 | POINT (531493.995 106639.488) |
| 2 | 2 | Site 3 | POINT (533356.778 105476.782) |
| 3 | 3 | Site 4 | POINT (528513.424 105052.43) |
| 4 | 4 | Site 5 | POINT (532421.163 109069.196) |
| 5 | 5 | Site 6 | POINT (528716.452 108042.794) |
Let’s also plot this data.
problem.plot_sites()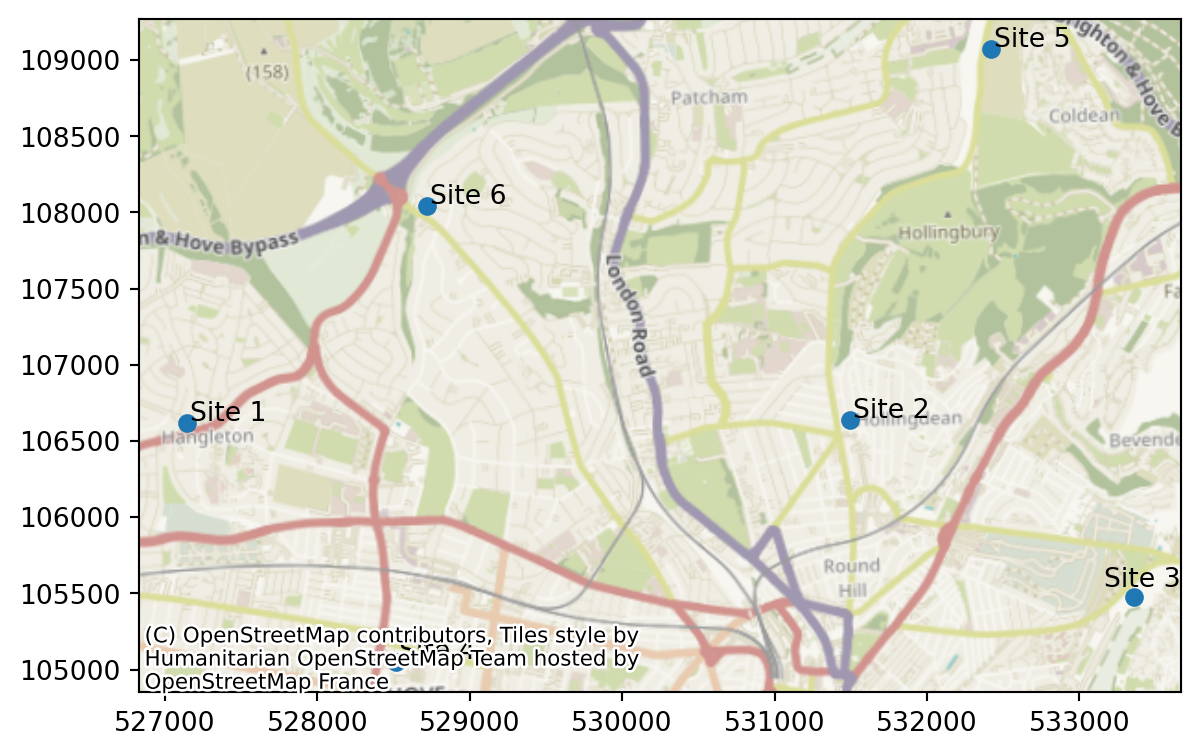
Now let’s solve the problem again, this time noticing that we can plot the site data.
solutions = problem.solve(p=3, objectives="simple_p_median")We can now plot the solution. This time, we’ll plot the 6 best solutions.
solutions.plot_n_best_combinations(n_best=5)(<Figure size 2880x576 with 6 Axes>,
array([<Axes: title={'center': 'Unweighted Average: 5.4 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Unweighted Average: 5.4 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Unweighted Average: 5.6 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Unweighted Average: 5.7 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Unweighted Average: 6.2 minutes \nMaximum: 16.7 minutes'}>],
dtype=object))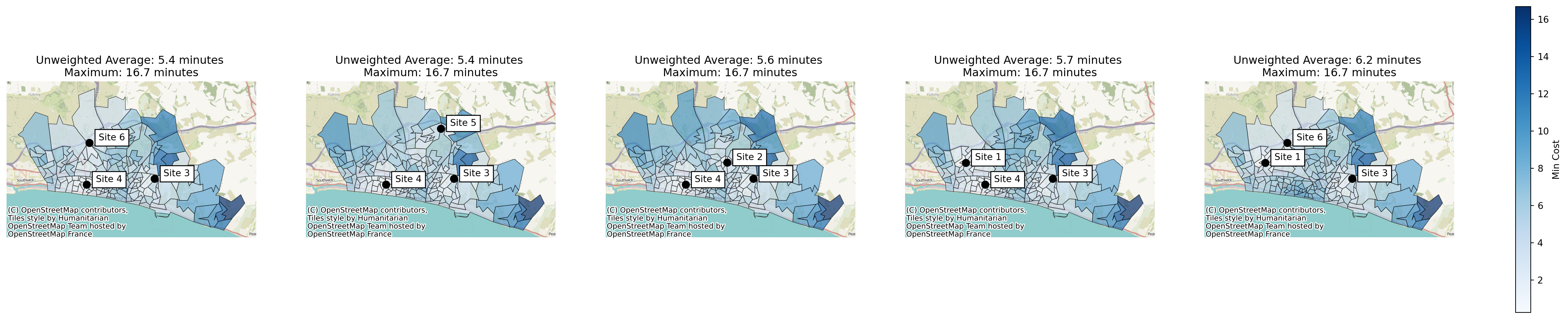
Demand Data
Finally, we can add in demand data.
With this, we can start exploring the ‘standard’ p-median problems, where the travel time is weighted by the number of people travelling from each region, which can support a more equitable solution.
Lokigi requires the demand data to contain a row per source region (i.e. where people will travel from).
problem.add_demand(
demand_df="../sample_data/brighton_demand.csv",
demand_col="demand",
location_id_col="LSOA"
)problem.show_demand()| LSOA | demand | |
|---|---|---|
| 0 | Brighton and Hove 027E | 3627 |
| 1 | Brighton and Hove 027F | 2323 |
| 2 | Brighton and Hove 027A | 2596 |
| 3 | Brighton and Hove 029E | 3132 |
| 4 | Brighton and Hove 029D | 2883 |
| ... | ... | ... |
| 160 | Brighton and Hove 012A | 2497 |
| 161 | Brighton and Hove 005C | 2570 |
| 162 | Brighton and Hove 012B | 2051 |
| 163 | Brighton and Hove 005A | 1164 |
| 164 | Brighton and Hove 005B | 1097 |
165 rows × 2 columns
When we plot our region, this time we can look at the demand.
problem.plot_region_geometry_layer(plot_demand=True)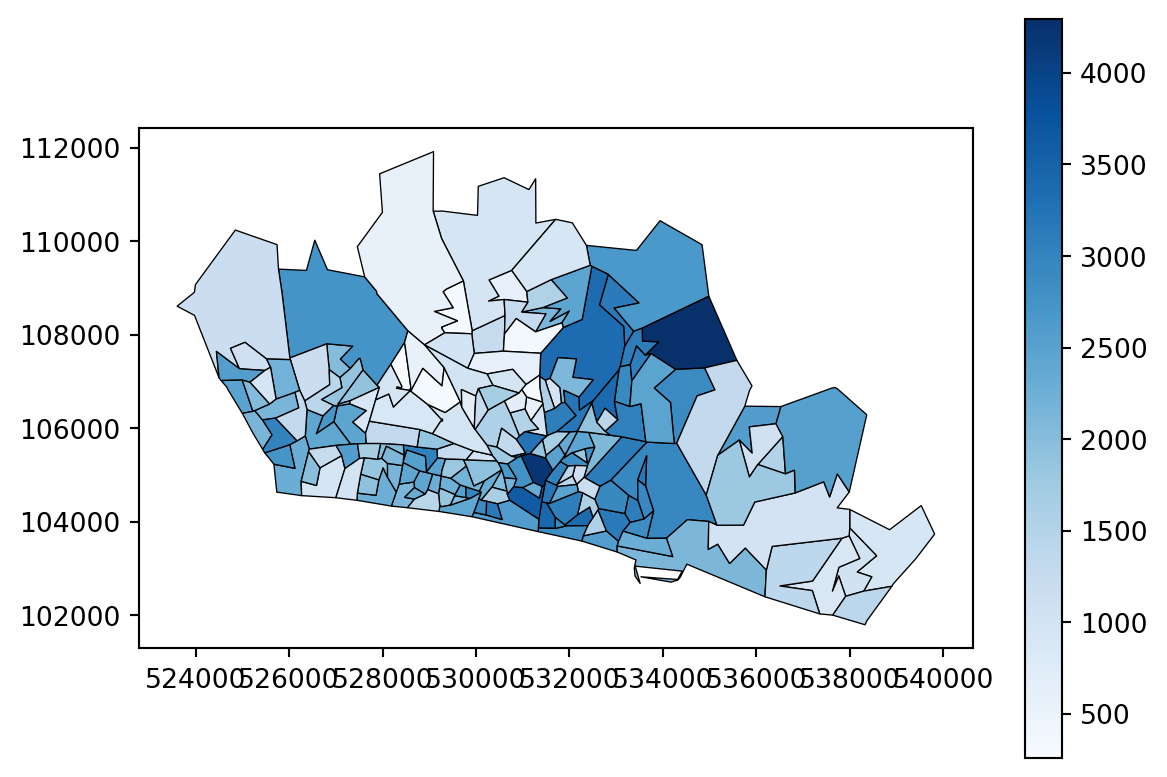
Now we can solve for a true p-median problem rather than a simplified one. This means that the weighted travel time - the travel time adjusted by the number of people travelling from each place - will be considered.
solutions = problem.solve(
p=3,
1 objectives="p_median"
)- 1
- Note that we have changed our objective from “simple_p_median” to “p_median” here. We haven’t had to change any other parts of our problem class, so we can easily run multiple different types of solver from our single problem class.
Tip
Want a more detailed explanation of weighted travel time? Take a look at the p-median problems subsection of the HSMA geographic book.
Let’s plot the solutions again.
solutions.plot_n_best_combinations(n_best=5)(<Figure size 2880x576 with 6 Axes>,
array([<Axes: title={'center': 'Weighted Average: 5.4 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Weighted Average: 5.4 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Weighted Average: 5.5 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Weighted Average: 5.5 minutes \nMaximum: 16.7 minutes'}>,
<Axes: title={'center': 'Weighted Average: 6.3 minutes \nMaximum: 16.7 minutes'}>],
dtype=object))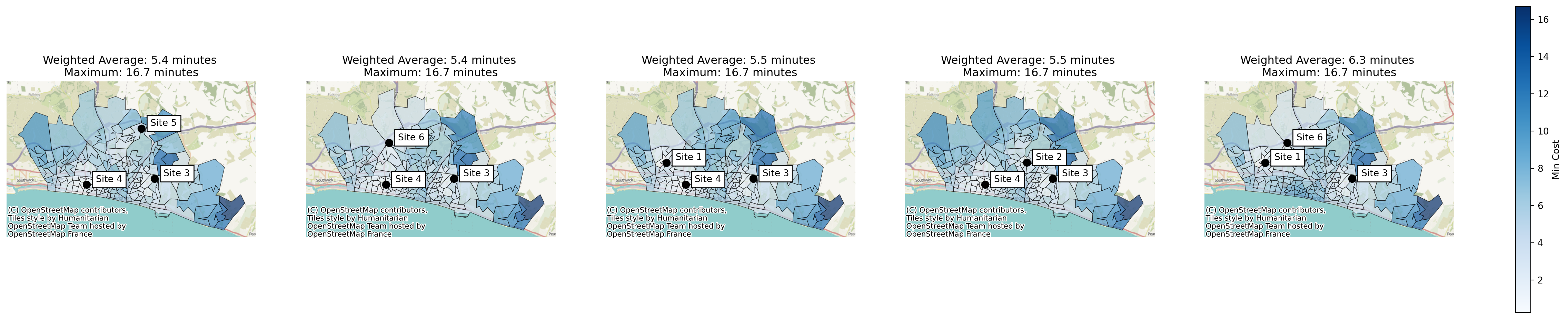
Recap - the data to add to your problem class
A more detailed breakdown of the allowed data is provided below.
| Input Data | Relevant Functions + mandatory parameters | Optional/Mandatory | Accepted Formats | Required Columns | Required Rows | Cell Contents | Commonalities |
|---|---|---|---|---|---|---|---|
| Travel/Cost Matrix |
|
Mandatory |
|
One column should represent the The remaining columns should be ‘Destinations’ (places people are travelling to) as columns |
‘Sources’ (regions people are travelling from) as rows | Cells are a figure to optimize on - e.g. travel time, distance, CO2 emissions | The ‘destinations’ column should have destinations in the same format as the region_geometry | | | The sources should match up with the site names used in the site locations dataset (if provided) | |
| Region Geometry |
|
Optional |
|
‘Geometry’, containing polygons or multipolygons of the regions of interest | There should be a row for each ‘source’ region | The rows in this dataframe should overlap with the rows in the ‘sources’ column of the travel/cost matrix | |
| Site Locations |
|
Optional |
|
A column representing the names of candidate sites AND either geometry containing points representing locations OR columns representing the positionof your sites. Defaults to looking for lat/long. |
One row per candidate site | Site names Locations of sites |
Site names should match the names of the columns provided in the travel/cost matrix |
| Demand |
|
Optional |
|
A column representing the regions Another column representing the demand or other weighting factor |
One row per region | A demand figure or another value that should be used to weight travel times | Row names should match the rows used for the travel matrix and region geometry |
Summary - the key object types
SiteProblem
The SiteProblem object is used to store all relevant data for the problem.
You initialise an empty SiteProblem, then run the methods detailed above to add the relevant datasets to the object.
You then call the .solve() method to create the SiteSolutionSet containing the ranked solutions.
SiteSolutionSet
A SiteSolutionSet is created by calling .solve() on your SiteProblem.
This object contains lot of methods for plotting the solutions.
EvaluatedCombination
Developer use only
During the process of generating solutions, an EvaluatedCombination object will be created for every evaluated set of sites. This is not directly available to you after you have solved your problem.